Proptech: Identifying Real Properties
Updated Thu, Mar 28, 2024 - 9 min read
“Location, location, location” is the common refrain in real estate. But in the proptech industry, we know that what comes first is “identification, identification, identification.” You cannot locate a property that you cannot identify.
Whether homes, commercial buildings, or any other type of real property, we must be able to distinguish individual properties in order to build systems to support them. Why? There are many sources of real estate information: deeds, tax assessor records, sales listings, building permits, and more. Proptech can leverage this rich data to provide products that understand the unique aspects and opportunities for each property. But it only works if we can connect the data from each source–for example, understanding that a deed refers to the same property as a sales listing and a building permit.
At first, this may appear to be easy. We all know how to identify our homes or businesses using addresses. But, as is often the case in the real world, the data behind common approaches such as addresses or geo coordinates is messy and inconsistent. There is no universal system of natural keys that can uniquely identify every property.
What follows is an overview of the important property identification systems for U.S. residences, with a summary of their strengths and drawbacks. Building property technology requires navigating multiple approaches while carefully avoiding pitfalls. This is how Kukun tackles the problem so our users have the most complete data possible about their homes.
Property Data at Kukun
Information about properties is central to Kukun’s products. Our data scientists use it in models that estimate the condition and value of homes (automated valuation models–“AVMs”). We relay it to homeowners through property dashboards, renovation cost estimators, and more. Everything hinges on knowing the details of each property. That requires us to understand data from many sources.
When we receive property data from different sources, we must match the properties between them. This is often difficult because each source can use a different identification system, or the particulars of the same system may vary between sources, such as with postal addresses that come in many different formats. If we cannot match a property, we may create duplicate records for it (each with an incomplete set of reference data), or we may not even be able to find the property for a customer.
Let's connect, and see how we can help you stay ahead of the market.
Contact us
In this context, we define a property as the smallest, separately segregated parcel of residential real property, the boundaries of which are set forth in a single deed. It is typically a single home, lot, or unit of a high-rise or multifamily building such as a condominium. The following sections describe the most common ways to identify them.
TL;DR Summary: The approaches to identifying properties include addresses, postal bar codes, geographic coordinates, assessor parcel numbers, parcel boundaries, and legal definitions. Each has benefits and limitations, and there is not a single perfect option. Successful proptech solutions often must support multiple approaches, with the ability to translate between them.
Read more: Real estate concepts
Addresses
Example: 330 Freeman Pkwy, Providence, RI 02906
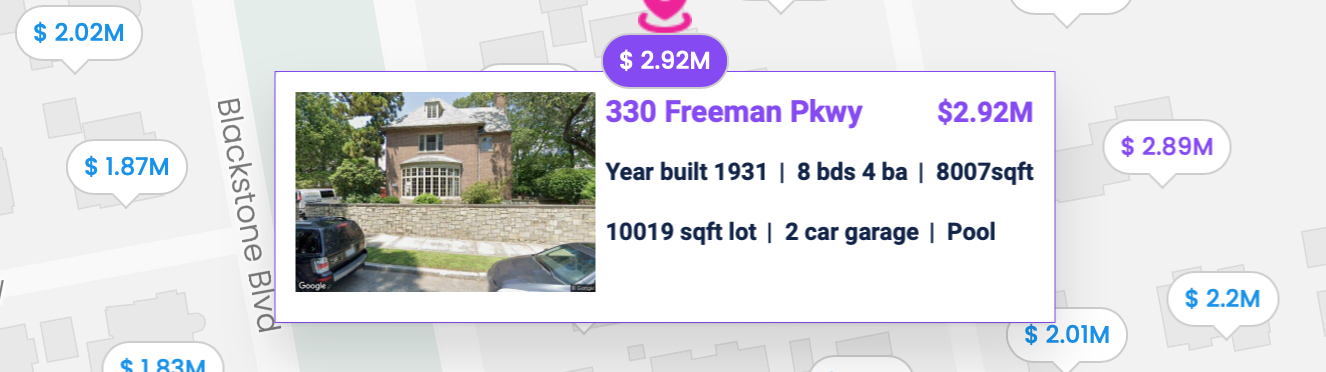
Addresses are the most popular way for people to refer to a property. This makes them the obvious choice for user inputs, such as allowing a user to look up their home in an app or website.
In the United States, the text of the address is composed of several fields, including street line 1, street line 2, secondary (suite or unit number), city, state, and zip code. Addresses are provided by users and also included in most property data sources.
There are standard rules for normalizing addresses, defined by the United States Postal Service (USPS). Following these rules make it more likely addresses from different sources can be matched, but this is not foolproof. Differences can be caused by many factors, such as different naming for the unit types in the secondary field (e.g. “Apt 21”, “Apartment 21”, “Unit 21”). In some cases, the same street can have multiple names. A news article from Boca Raton, Florida explains the dual naming of streets such as a “76th Street” being given the second name, “Orchid Bay Drive.” The article helpfully notes that “residents will be allowed to use either the new or old name for mail.” That may be a benefit for the residents, but it makes it hard for property technology to retrieve data when government or commercial records use one street name, and the user provides another. Navigating such differences can require sourcing and maintaining a database of street name aliases.
Benefits
- Readily recognized and understood by users
- Cleaning and normalization may not be required for addresses from commercial data sets
Drawbacks
- User inputs require cleaning and normalization before use
- Need to compare multiple string fields in order to match properties, making it challenging to do fast look-ups on property databases that can exceed 150 million entries
- Text fields for the same property are not guaranteed to always normalize to the same thing, requiring fuzzy matching logic to detect if two addresses refer to the same property. This makes it even harder to build fast matching.
- Some properties do not have postal addresses and cannot be represented this way
Postal Bar Code
Example: 90265431738

The USPS provides another way to represent postal addresses: an 11-digit code that uniquely represents every point to which mail is delivered, typically mailboxes. It is typically printed on mail as a barcode, but in a database can be stored as an 11-digit number.
Benefits
- Uses a single numeric value to identify a unique property, offering potential for fast look-ups
Drawbacks
- Users and commercial data sets do not provide this code
- Converting address text to postal bar codes is complex, requiring certification from the USPS on your system’s adherence to their Coding Accuracy Support System
- Some properties do not have postal addresses and cannot be represented this way
Geographic Coordinates
Example: 34.01517, -118.79128

There are many geocoding services available which can translate a street address to latitude and longitude coordinates. So while coordinates are not addresses, they can be used to represent the home’s location in a similar way, and are translatable back and forth. Since the coordinates are numeric values, they have the potential to be easier to work with.
Benefits
- Many services and systems have the ability to geocode addresses to lat/long, and many commercial property data sets already include these coordinates
- Uses two numeric values to identify a unique property, offering the potential for fast look-ups (mitigated by the imprecision noted below, which may require fuzzy matching)
- Can work for properties that do not have postal addresses
Drawbacks
- There are many possible lat/long coordinates for each property, because properties cover an area, not a single point. The exact values selected usually vary between different geocoders and over time as their data and algorithms change. Matching coordinates from different sources requires fuzzy matching which is slower and prone to mismatches
- Does not work well for high rise buildings where units are stacked
Assessor Parcel Number (APN)
Example: 4466-003-009
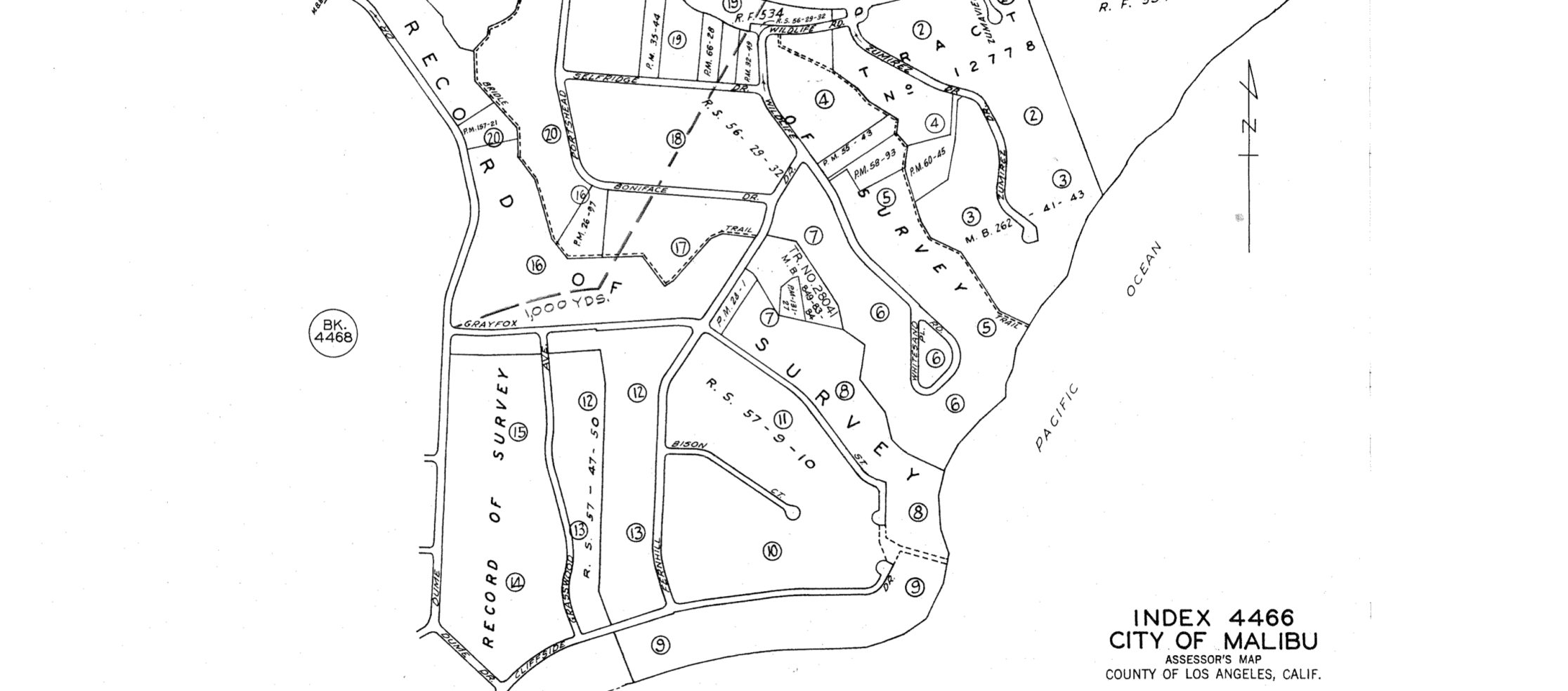
The APN is a unique code assigned to each property by its local taxing authority for identification and record-keeping. As such, a property can be uniquely referenced by a combination of its local jurisdiction (usually county) and APN. In many government data sets, such as deeds and assessor records, this is the primary identifier for properties. Because of this, handling APNs can be a convenient or even necessary part of property technology.
There is not a standard format for APNs, so each jurisdiction may generate them differently, requiring storing them as variable-length strings. The example above was created by Los Angeles County, and is a concatenation of a county survey map number (4466), sheet number (3), and lot number (9).
Benefits
- Native to government records, which are an important source of property data
- Uses a single string to represent a unique property, offering the potential for fast look-ups
- Can work for properties that do not have postal addresses
Drawbacks
- Not familiar to many people, so not a good choice for user inputs
- Not easily derived–looking them up requires a database that maps them to other identifiers, such as addresses or geo coordinates
- Not always unique for an individual home–there are cases where multiple homes with different addresses are located on a single lot
Parcel Boundaries
These are a generalization of geographic coordinates. Instead of representing a property as a single point, parcel boundaries represent them as a polygon that encloses a set of geographic points. This can provide more precision, and remove the need for fuzzy matching. However, there are fewer sources for parcel boundaries, and using them can be complex for many applications. They may work well for user interfaces with maps, allowing the user to tap on any point in the property.
Benefits
- Precise–encodes the actual boundaries of a property
Drawbacks
- Not concise–each property is represented by a variable-length series of geographic coordinates
- Sourcing them can be a challenge, as they are only available from a limited number of commercial GIS data providers
- Does not work well for high rise buildings where units are stacked
Legal Definition
Example: TR=12778 POR OF LOT 21
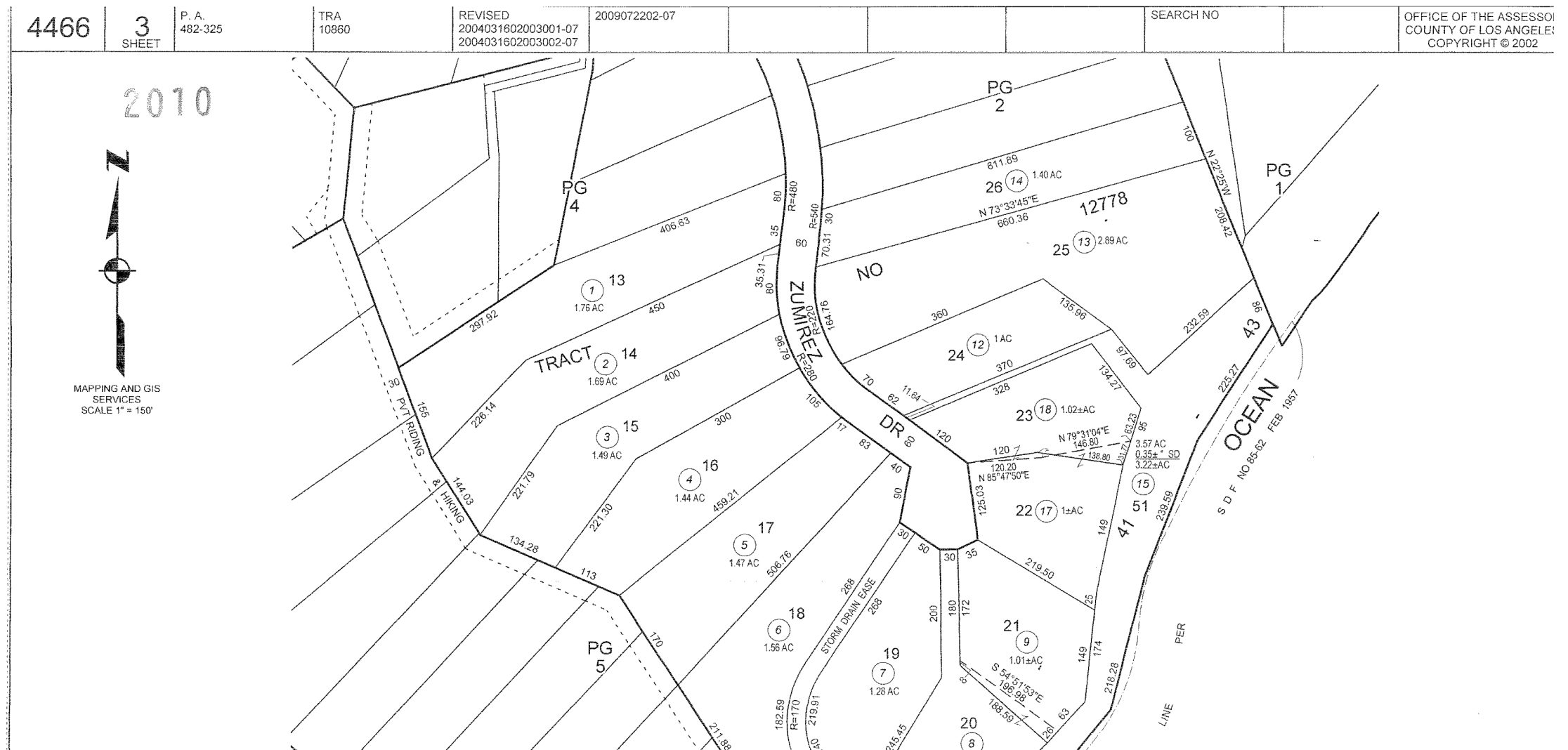
Deeds and other government records contain a legal definition of a property. However, other than in legal documents, these are not in common use and are hard to work with. They can also be subject to format differences, as they were designed to be read by surveyors and lawyers, not machines. In the example above from Los Angeles County, the legal definition of the property is a portion of Lot 21 in Tract Number 12778. Interpreting these values often requires consulting images of (sometimes hand-drawn) survey maps to see the location of tracts and lots, and in this case, which portion of Lot 21 is included.
Benefits
- Available in many government records. Useful if you are a real estate attorney or selling title insurance
Drawbacks
- Not concise or standardized
- Not easily derived–looking them up requires a database that maps them to other identifiers
How you should use these systems depends on your use case and data sources. At Kukun, we use a combination of these identifiers, with systems built to map between them as needed in order to maximize both speed and the amount of data available. By being thorough and using multiple data points on properties, Kukun provides its users with quality data and insights. We hope that this article also provides you with insight on how to navigate the complexities of identifying properties, and we welcome your feedback and ideas.
Matthew Nichols
Matthew Nichols is the VP of Engineering at Kukun, where he leads innovation in property and finance technology. After receiving his M.S. in Electrical and Computer Engineering from the University of Illinois at Urbana-Champaign, Matt spent fifteen years at Expedia Group, where he held various key roles, including Sr. Director of Technology and Director of Software Development. During his tenure, he led teams in developing cutting-edge solutions for the travel industry, including scalable multi-tenant services and real-time data platforms.
Published August 22, 2023